Architecture#
Introduction#
PynPoint has evolved from a PSF subtraction toolkit to an end-to-end pipeline for processing and analysis of high-contrast imaging data. The architecture of PynPoint was redesigned in v0.3.0 with the goal to create a generic, modular, and open-source data reduction pipeline, which is extendable to new data processing techniques and data types.
The actual pipeline and the processing modules have been separated in a different subpackages. Therefore, it is possible to extend the processing functionalities without intervening with the core of the pipeline. The UML class diagram below illustrates the pipeline architecture:
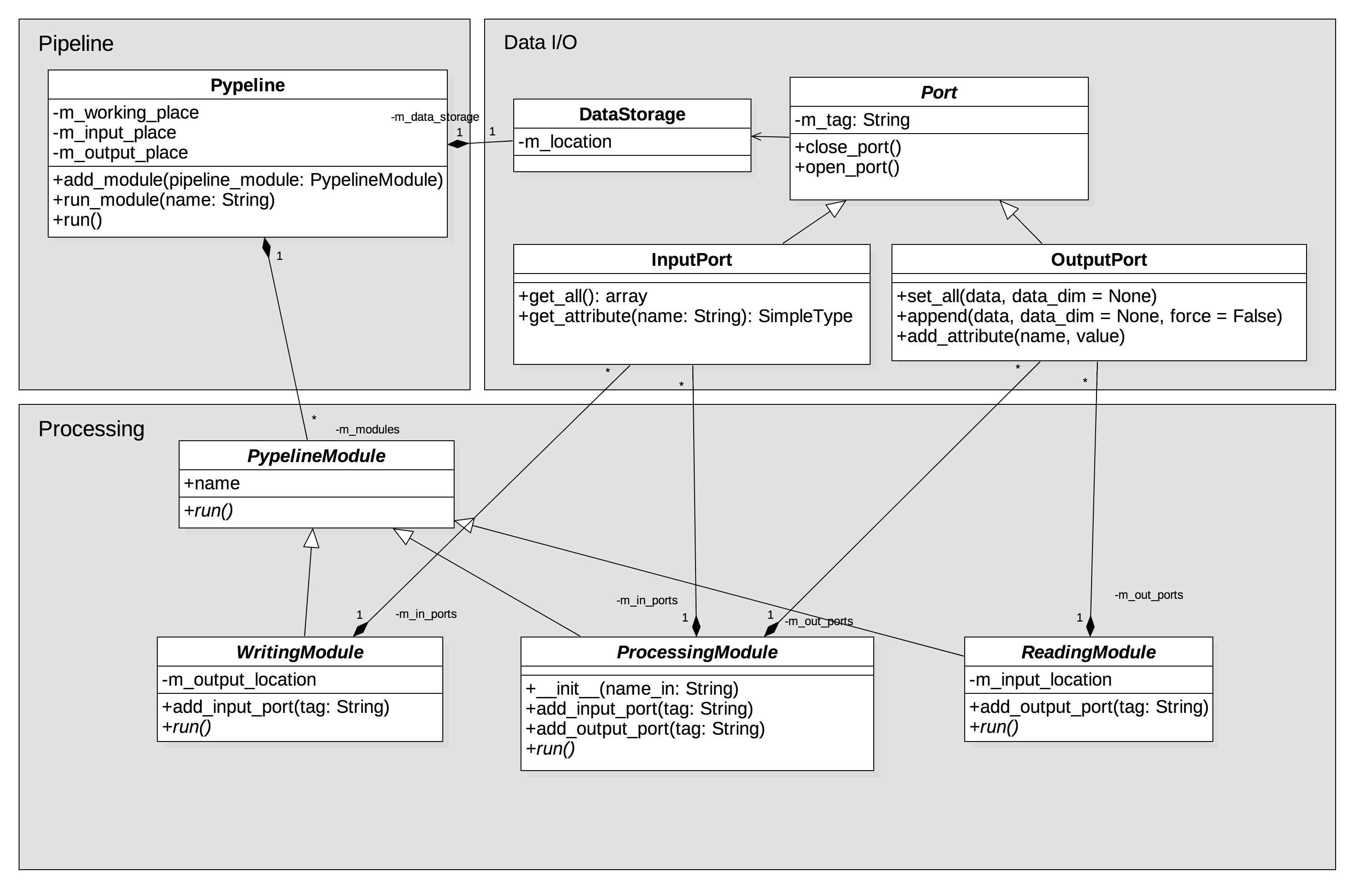
The diagram shows that the architecture is subdivided in three components:
Data management:
pynpoint.core.dataioPipeline modules for reading, writing, and processing of data:
pynpoint.core.processingThe actual pipeline:
pynpoint.core.pypeline
Central database#
The data management has been separated from the data processing for the following reasons:
Raw datasets can be very large (in particular in the 3–5 μm regime) which challenges the processing on a computer with a small amount of memory (RAM). A central database is used to store the data on a computer’s hard drive.
Some data is used in different steps of the pipeline. A central database makes it easy to access that data without making a copy.
The central data storage on the hard drive will remain updated after each step. Therefore, processing steps that already finished remain unaffected if an error occurs or the data reduction is interrupted by the user.
Understanding the central data storage classes can be helpful with the development of new pipeline modules (see Coding a new module). When running the pipeline, it is sufficient to understand the concept of database tags.
Each pipeline module has input and/or output tags which point to specific dataset in the central database. A module with image_in_tag='im_arr' will read the input images from the central database under the tag name im_arr. Similarly, a module with image_out_tag='im_arr_processed' will store a the processed images in the central database under the tag im_arr_processed.
Accessing the data storage occurs through instances of Port which allows pipeline modules to read data from and write data to database.
Pipeline modules#
A pipeline module has a specific task that is appended to the internal queue of a Pypeline instance. Pipeline modules can read and write data tags from and to the central database through dedicated input and output connections. There are three types of pipeline modules:
pynpoint.core.processing.ReadingModule- A module with only output tags/ports, used to read data to the central database.
pynpoint.core.processing.WritingModule- A module with only input tags/ports, used to export data from the central database.
pynpoint.core.processing.ProcessingModule- A module with both input and output tags/ports, used for processing of the data.
Typically, a ProcessingModule reads one or multiple datasets from the database, applies a specific processing task with user-defined parameter values, and stores the results as a new dataset in the database.
In order to create a valid data reduction cascade, one should check that the required input tags are linked to data which were previously created by another pipeline module. In other words, there needs to be a previous module which has stored output under that same tag name.
Pypeline#
The pypeline module is the central component which manages the order and execution of the different pipeline modules. Each Pypeline instance has an working_place_in path which is where the central database and configuration file are stored, an input_place_in path which is the default data location for reading modules, and an output_place_in path which is the default output path where the data will be saved by the writing modules:
from pynpoint import Pypeline, FitsReadingModule
pipeline = Pypeline(working_place_in='/path/to/working_place',
input_place_in='/path/to/input_place',
output_place_in='/path/to/output_place')
A pipeline module is created from any of the classes listed in the Pipeline modules section, for example:
module = FitsReadingModule(name_in='read', image_tag='input')
The module is appended to the pipeline queue as:
pipeline.add_module(module)
And can be removed from the queue with the following method:
pipeline.remove_module('read')
The names and order of the pipeline modules can be listed with:
pipeline.get_module_names()
Running all modules attached to the pipeline is achieved with:
pipeline.run()
Or a single module is executed as:
pipeline.run_module('read')
Both run methods will check if the pipeline has valid input and output tags.
An instance of Pypeline can be used to directly access data from the central database. See the HDF5 database section for more information.